Welcome to IGNNITION
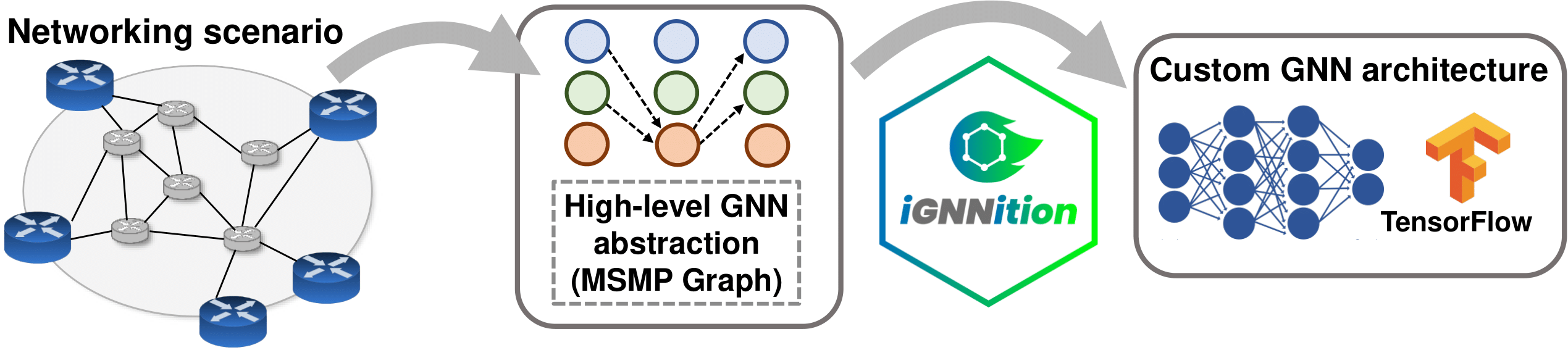
Graph Neural Networks (GNNs) are becoming increasingly popular in communication networks, where many problems are formulated as graphs with complex relationships (e.g., topology, routing, wireless channels). However, implementing a GNN model is nowadays a complex and time-consuming task, especially for scientists and engineers of the networking field, which often lack a deep background in neural network programming (e.g., TensorFlow or PyTorch). This arguably prevents networking experts to apply this type of neural networks to their specific problems. IGNNITION is a TensorFlow-based framework for fast prototyping of GNNs. It provides a codeless programming interface, where users can implement their own GNN models in a YAML file, without writing a single line of TensorFlow. With this tool, network engineers are able to create their own GNN models in a matter of few hours. IGNNITION also incorporates a set of tools and functionalities that guide users during the design and implementation process of the GNN. Check out our quick start tutorial to start using IGNNITION. Also, you can visit our examples library with some of the most popular GNN models applied to communication networks already implemented.
MSMP definition
Getting started
Installation
Visit installation to have a detailed tutorial on how to install IGNNITION and all its necessary dependencies.
IGNNITION at a glance
In the section ignnition at a glance, we provide an overview of the benefits of using IGNNITION with respect of traditional tools for the implementation of custom GNN models.
Quick step-by-step tutorial
Because we believe that the best way to learn is by practicing, we provide in quick step-by-step tutorial an example of how to implement a GNN from scratch, which should be a good starting point for any user.
About
Learn more in About us, about Barcelona Neural Networking Center team which has carried out the development of IGNNITION.
License
Despite being an open-source project, in section License we provide the details on the released license.